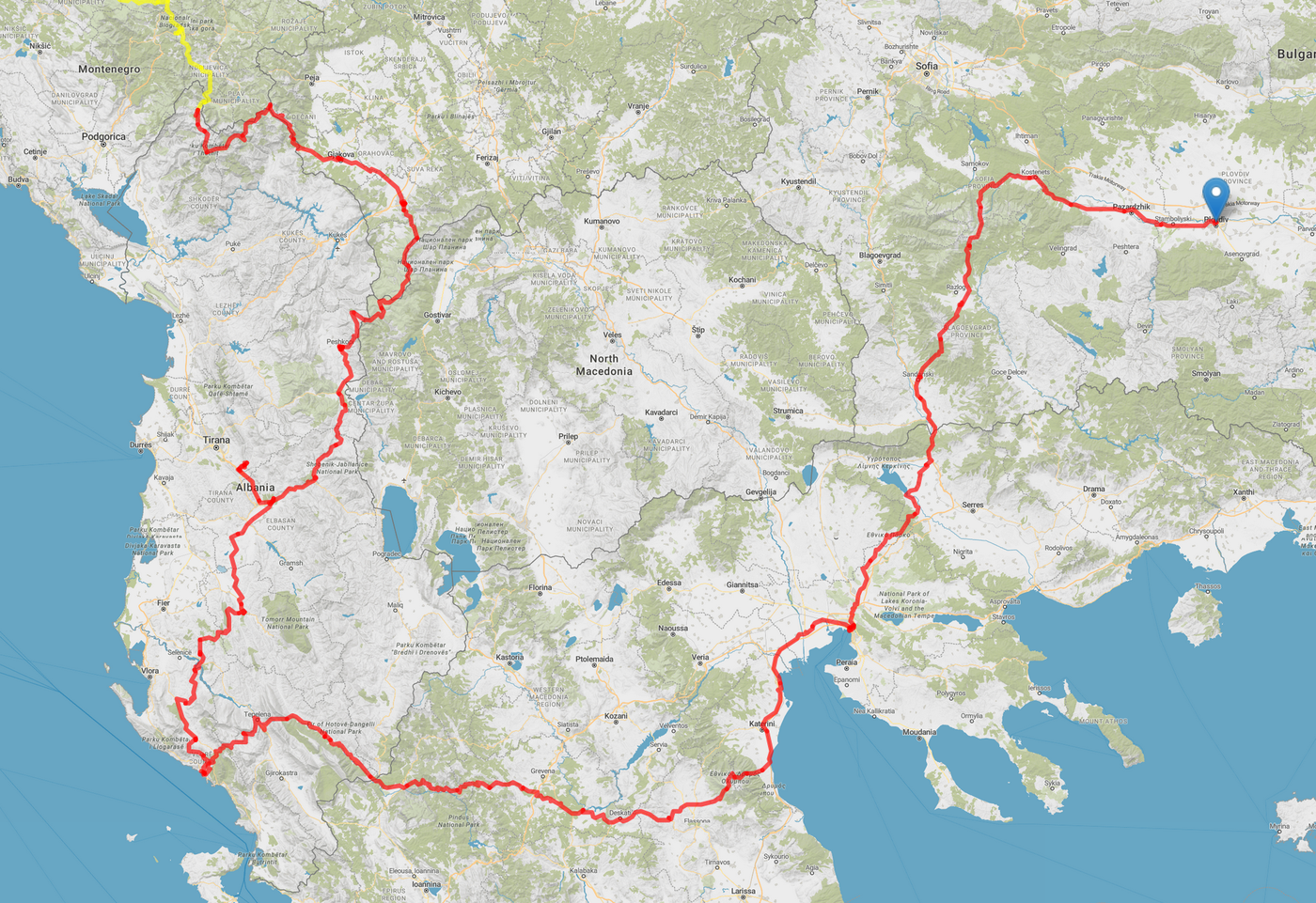
# Imports
from collections import Counter
-from dataclasses import dataclass, field
+from dataclasses import dataclass, field, asdict
from hashlib import md5
from pathlib import Path
from shutil import copyfile
from subprocess import run
from typing import List, Dict, Any, Tuple
+from typing_extensions import TypedDict
import asyncio
import datetime
import logging
@@ -73,11 +74,11 @@ class SiteMetadata:
words: Dict[str, int] = field(
default_factory=lambda: {"drafts": 0, "references": 0, "self": 0}
)
- links: Dict[str, set] = field(
+ links: Dict[str, Any] = field(
default_factory=lambda: {
- "internal": set(),
+ "internal": list(),
+ "backlinks": list(),
"external": set(),
- "backlinks": set(),
}
)
pagecount: int = 0
@@ -91,9 +92,15 @@ class SiteMetadata:
slug_to_title_lookup: Dict[str, str] = field(default_factory=dict)
+class LinksDict(TypedDict):
+ internal: list[str]
+ external: list[str]
+ backlinks: list[str]
+
+
@dataclass
class DocumentMetadata:
- filename: Path
+ filepath: Path
uid: str
slug: str
created: datetime.datetime
@@ -102,20 +109,78 @@ class DocumentMetadata:
title: str
primary: str
secondary: str
+ creator: str = ""
+ note: str = ""
+ favourite: bool = False
+ parent: str = ""
+ description: str = ""
+ layout: str = TEMPLATE_DEFAULT
+ source: Dict = field(default_factory=dict)
+ via: Dict = field(default_factory=dict)
+ location: Dict = field(default_factory=dict)
+ collection: Dict[str, Any] = field(
+ default_factory=lambda: {
+ "style": "title",
+ "order": "chronological",
+ "include": [],
+ }
+ )
+ attribution: Dict[str, str] = field(
+ default_factory=lambda: {
+ "plain": "",
+ "djot": "",
+ "html": "",
+ }
+ )
+ media: str = "application/toml"
words: int = 0
- links: Dict[str, set] = field(
+ status: str = ""
+ links: LinksDict = field(
default_factory=lambda: {
- "internal": set(),
- "external": set(),
- "backlinks": set(),
+ "internal": list(),
+ "external": list(),
+ "backlinks": list(),
}
)
options: List[str] = field(default_factory=list)
tags: List[str] = field(default_factory=list)
- interlinks: List[str] = field(default_factory=list)
- backlinks: List[str] = field(default_factory=list)
content: Dict[str, str] = field(default_factory=dict)
- html: str = ""
+
+ def __post_init__(self):
+ # Validate required string fields are not empty
+ # for field_name in ["uid", "slug", "title", "primary", "secondary"]:
+ # value = getattr(self, field_name)
+ # if not isinstance(value, str) or not value.strip():
+ # raise ValueError(f"\n\n{self}\n\n{field_name} {value} must be a non-empty string"\n)
+
+ # Validate filepath is a Path object
+ if not isinstance(self.filepath, Path):
+ self.filepath = Path(self.filepath)
+
+ ## Validate datetime fields
+ # for field_name in ["created", "updated", "available"]:
+ # value = getattr(self, field_name)
+ # if not isinstance(value, datetime.datetime):
+ # raise ValueError(f"{field_name} must be a datetime object")
+ # # Ensure timezone is None
+ # setattr(self, field_name, value.replace(tzinfo=None))
+
+ # Validate words is non-negative
+ if not isinstance(self.words, int) or self.words < 0:
+ raise ValueError("words must be a non-negative integer")
+
+ # Validate links dictionary structure
+ required_link_types = {"internal", "external", "backlinks"}
+ if (
+ not isinstance(self.links, dict)
+ or set(self.links.keys()) != required_link_types
+ ):
+ raise ValueError(
+ f"links must be a dictionary with exactly these keys: {required_link_types}"
+ )
+ for key in self.links:
+ if not isinstance(self.links[key], set):
+ self.links[key] = set(self.links[key])
def init_site():
@@ -132,12 +197,47 @@ def init_site():
)
-def load_assets():
+def preprocess_asset_metadata(
+ uid: str, asset_data: Dict[str, Any], manifest_path: Path
+) -> Dict[str, Any]:
+ """Preprocess asset metadata to ensure it meets DocumentMetadata requirements."""
+ processed = asset_data.copy()
+
+ # Handle dates
+ for date_field in ["created", "updated", "available"]:
+ if isinstance(processed.get(date_field), str):
+ processed[date_field] = _parse_date(processed[date_field])
+ elif isinstance(processed.get(date_field), datetime.datetime):
+ processed[date_field] = processed[date_field].replace(tzinfo=None)
+ else:
+ processed[date_field] = datetime.datetime.now()
+
+ # Set required fields with defaults if not present
+ processed.setdefault("uid", uid)
+ processed.setdefault("primary", "asset")
+ processed.setdefault("secondary", processed["media"])
+
+ return processed
+
+
+def load_assets() -> Dict[str, DocumentMetadata]:
+ """Load asset manifests and convert them to DocumentMetadata instances."""
assets = {}
asset_manifests = list(ASSET_DIR.glob("manifests/*.toml"))
+
for manifest in asset_manifests:
with open(manifest, "rb") as f:
- assets.update(tomllib.load(f))
+ manifest_data = tomllib.load(f)
+
+ for uid, asset_data in manifest_data.items():
+ try:
+ processed_data = preprocess_asset_metadata(uid, asset_data, manifest)
+ processed_data["filepath"] = ASSET_DIR / processed_data["filepath"]
+ assets[uid] = DocumentMetadata(**processed_data)
+ except Exception as e:
+ print(f"Error processing asset {uid} from {manifest}: {str(e)}")
+ continue
+
return assets
@@ -176,7 +276,7 @@ def get_files() -> List[Path]:
return [f for f in NOTES_DIR.glob("**/*.md") if "available = " in f.read_text()]
-def extract_external_links(text: str) -> List:
+def extract_external_links(text: str, site) -> List:
url_pattern = r"(https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+(?:/[^)\s]*)?)"
matches = re.findall(url_pattern, text)
@@ -186,18 +286,21 @@ def extract_external_links(text: str) -> List:
parsed_url = urlparse(url)
if parsed_url.netloc.lower() != "silasjelley.com":
external_links.add(url)
+ site.links["external"].add(url)
- return list(external_links)
+ return sorted(external_links)
async def process_document(
- filename: Path, site: SiteMetadata
-) -> Tuple[str, Dict[str, Any]]:
- with open(filename, "rb") as f:
+ filepath: Path, site: SiteMetadata
+) -> Tuple[str, DocumentMetadata]:
+ """Process a document file and return its UID and metadata."""
+
+ with open(filepath, "rb") as f:
try:
parsed_toml = tomllib.load(f)
except:
- print(filename)
+ print(filepath)
import sys
sys.exit(1)
@@ -205,52 +308,48 @@ async def process_document(
# The UID is now the top-level table name
uid = parsed_toml["uid"]
- # Preprocess metadata (assuming this function exists and works with the new format)
- document = preprocess_metadata(filename, parsed_toml)
+ # Process metadata into DocumentMetadata instance
+ document = preprocess_metadata(filepath, parsed_toml)
# Calculate and update word counts
try:
- document["words"] = len(document["content"]["plain"].split())
+ document.words = len(document.content.get("plain", "").split())
except:
- document["words"] = 0
+ document.words = 0
- if document.get("status", "") == "draft":
- site.words["drafts"] += document["words"]
+ if document.status == "draft":
+ site.words["drafts"] += document.words
else:
try:
- document["source"]["words"] = len(document["source"]["text"].split())
- site.words["references"] += document["source"]["words"]
+ source_words = len(document.source.get("text", "").split())
+ site.words["references"] += source_words
except KeyError:
pass
try:
- site.words["self"] += document["words"]
+ site.words["self"] += document.words
except:
pass
# Extract external links from the plain text content
try:
- plain_text = document.get("content", {}).get("plain", "") + " "
- plain_text += document.get("source", {}).get("url", "") + " "
- plain_text += document.get("via", {}).get("url", "") + " "
-
- external_links = extract_external_links(plain_text)
+ plain_text = (
+ document.content.get("plain", "")
+ + " "
+ + document.source.get("url", "")
+ + " "
+ + document.via.get("url", "")
+ )
- # Store the external links in document["links"]["external"]
- document["links"] = {
- "internal": set(),
- "external": set(),
- "backlinks": set(),
- }
- document["links"]["external"].update(external_links)
- site.links["external"].update(external_links)
+ external_links = extract_external_links(plain_text, site)
+ document.links["external"] = external_links
except KeyError:
- print(f"KeyError while compiling external links from {document['filename']}")
+ print(f"KeyError while compiling external links from {document.filepath}")
pass
return uid, document
-async def ingest_documents(site: SiteMetadata) -> Dict[str, Dict[str, Any]]:
+async def ingest_documents(site: SiteMetadata) -> Dict[str, Any]:
logger.info("Ingesting files")
file_list = get_files()
documents = {}
@@ -258,11 +357,9 @@ async def ingest_documents(site: SiteMetadata) -> Dict[str, Dict[str, Any]]:
slug_to_uid_lookup = {}
site_primaries = set()
site_secondaries = set()
- site_series = set()
- tags = set()
uuid_collision_lookup = []
- tasks = [process_document(filename, site) for filename in file_list]
+ tasks = [process_document(filepath, site) for filepath in file_list]
results = await asyncio.gather(*tasks)
site.words["total"] = (
site.words["drafts"] + site.words["references"] + site.words["self"]
@@ -270,13 +367,11 @@ async def ingest_documents(site: SiteMetadata) -> Dict[str, Dict[str, Any]]:
for uid, doc in results:
documents[uid] = doc
- slug_to_title_lookup[doc["slug"]] = doc["title"]
- slug_to_uid_lookup[doc["slug"]] = uid
- site_primaries.add(doc["primary"])
- site_secondaries.add(doc["secondary"])
- if "series" in doc:
- site_series.add(doc["series"])
- tags.update(doc.get("tags") or [])
+ slug_to_title_lookup[doc.slug] = doc.title
+ slug_to_uid_lookup[doc.slug] = uid
+ site_primaries.add(doc.primary)
+ site_secondaries.add(doc.secondary)
+ site.tags += doc.tags
uuid_collision_lookup.append(uid)
site.slug_to_uid_lookup = slug_to_uid_lookup
@@ -284,7 +379,6 @@ async def ingest_documents(site: SiteMetadata) -> Dict[str, Dict[str, Any]]:
check_uuid_collisions(uuid_collision_lookup)
site.primaries = list(site_primaries)
site.secondaries = list(site_secondaries)
- site.tags = list(tags)
site.pagecount = len(documents)
logger.info(f"Ingested {site.pagecount} files")
@@ -373,14 +467,14 @@ def process_image_parallel(input_data: Tuple[Path, Path, int, str]) -> None:
def process_assets(
- assets: Dict[str, Dict[str, Any]], asset_dir: Path, output_dir: Path
+ assets: Dict[str, DocumentMetadata], asset_dir: Path, output_dir: Path
) -> None:
logger.info("Processing assets")
manifest_images = []
for asset_identifier, asset_metadata in assets.items():
- source_path = Path(asset_metadata["filepath"])
- output_path = output_dir / asset_metadata["slug"]
+ source_path = Path(asset_metadata.filepath)
+ output_path = output_dir / asset_metadata.slug
os.makedirs(output_path.parent, exist_ok=True)
if not source_path.exists():
@@ -422,74 +516,52 @@ def _parse_date(date_str: str) -> datetime.datetime:
return datetime.datetime.strptime(date_str, "%Y-%m-%d").replace(tzinfo=None)
-def preprocess_metadata(filename: Path, metadata: Dict[str, Any]) -> Dict[str, Any]:
- """Preprocesses metadata for a document, ensuring required fields exist and formatting data."""
-
- metadata["filename"] = filename
-
- # Validate required fields
- required_fields = ["uid", "slug", "available", "created", "primary", "secondary"]
- missing_fields = [field for field in required_fields if field not in metadata]
- if missing_fields:
- raise ValueError(
- f"[ERROR] Document missing {', '.join(missing_fields)}\n {filename}"
- )
-
- # Set default values
- metadata.setdefault("updated", metadata["created"])
+def preprocess_metadata(filepath: Path, metadata: Dict[str, Any]) -> DocumentMetadata:
+ """Preprocesses metadata for a document and converts it to a DocumentMetadata instance."""
+ # Create a working copy to avoid modifying the input
+ processed = metadata.copy()
# Parse date fields
for date_field in ["created", "updated", "available"]:
- if date_field in metadata:
- if isinstance(metadata[date_field], str):
- metadata[date_field] = _parse_date(metadata[date_field])
- elif isinstance(metadata[date_field], datetime.datetime):
- metadata[date_field] = metadata[date_field].replace(tzinfo=None)
-
- # Process source information
- if "source" in metadata:
- if "via" in metadata:
- metadata.update(
- process_source_information(metadata["source"], metadata["via"])
- )
- else:
- metadata.update(process_source_information(metadata["source"], {}))
+ if isinstance(processed.get(date_field), str):
+ processed[date_field] = _parse_date(processed[date_field])
+ elif isinstance(processed.get(date_field), datetime.datetime):
+ processed[date_field] = processed[date_field].replace(tzinfo=None)
+
+ # Set default updated time if not provided
+ processed.setdefault("updated", processed.get("created"))
+
+ # Process source information if present
+ if "source" in processed:
+ processed["attribution"] = process_source_information(
+ processed["source"], processed.get("via", {})
+ )
+ else:
+ processed["attribution"] = {}
+ processed["source"] = {}
+
+ if "via" not in processed:
+ processed["via"] = {}
# Determine title
- metadata["title"] = (
- metadata.get("title")
- or metadata.get("attribution", {}).get("plain")
- or metadata["created"].strftime("%B %e, %Y %-I.%M%p")
+ processed["title"] = (
+ processed.get("title")
+ or processed.get("attribution", {}).get("plain")
+ or processed["created"].strftime("%B %e, %Y %-I.%M%p")
)
- # Ensure title and slug are strings
- metadata["title"] = str(metadata["title"])
- if metadata.get("status") == "draft":
- metadata["slug"] = "drafts/" + metadata["uid"]
- metadata["parent"] = "a26221ae-c742-4b73-8dc6-7f8807456a1b"
- else:
- metadata["slug"] = str(metadata["slug"])
- # Initialize interlinks, backlinks, and tags
- metadata["interlinks"] = set()
- metadata["backlinks"] = set()
- metadata["tags"] = metadata.get("tags") or []
+ # Handle draft status
+ if processed.get("status") == "draft":
+ processed["slug"] = f"drafts/{processed['uid']}"
- # Strip whitespace from plain content
- try:
- metadata["content"]["plain"] = metadata["content"]["plain"].strip()
- except KeyError:
- pass
- try:
- metadata["source"]["text"] = metadata["source"]["text"].strip()
- except KeyError:
- pass
+ # Add filepath as it's required but comes from function parameter
+ processed["filepath"] = filepath
- return metadata
+ # Create and return DocumentMetadata instance
+ return DocumentMetadata(**processed)
-def process_source_information(
- source: Dict[str, Any], via
-) -> Dict[str, Dict[str, str]]:
+def process_source_information(source: Dict[str, Any], via) -> Dict[str, str]:
creator = source.get("creator") or source.get("director")
title = source.get("title") or (
" ♫ " + str(source.get("track"))
@@ -587,13 +659,11 @@ def process_source_information(
partsvia = f" ([via]({escape_url(via["url"])}))"
return {
- "attribution": {
- "plain": f"{speaker}{', '.join(partsplain + partsshared)}",
- "djot": f"{speaker}{', '.join(partsdjot + partsshared)}",
- "html": format_rich_attribution(
- " — " + f"{speaker}{', '.join(partshtml + partsshared) + partsvia}"
- ),
- }
+ "plain": f"{speaker}{', '.join(partsplain + partsshared)}",
+ "djot": f"{speaker}{', '.join(partsdjot + partsshared)}",
+ "html": format_rich_attribution(
+ " — " + f"{speaker}{', '.join(partshtml + partsshared) + partsvia}"
+ ),
}
@@ -619,8 +689,8 @@ def check_uuid_collisions(uuid_list):
def insert_substitutions(
- documents: Dict[str, Dict[str, Any]],
- assets: Dict[str, Dict[str, Any]],
+ documents: Dict[str, DocumentMetadata],
+ assets: Dict[str, DocumentMetadata],
site: SiteMetadata,
) -> None:
logger.info("Performing substitutions")
@@ -635,53 +705,56 @@ def insert_substitutions(
merged_data = {**documents, **assets}
for key, page in documents.items():
- logger.debug(f" {key}, {page['title'][:40]}")
+ logger.debug(f" {key}, {page.title[:40]}")
- text = page.get("content", {}).get("plain")
+ text = page.content.get("plain")
if text:
text = replace_import_references(text, REF_IMPT_RE, merged_data, key, page)
text = replace_cite_references(text, REF_CITE_RE, merged_data)
text = replace_title_references(text, REF_TITLE_RE, merged_data)
text = replace_slug_references(text, REF_SLUG_RE, merged_data)
text = process_reference_links(text, REF_LINK_RE, merged_data, key)
- page["content"]["plain"] = text.strip()
+ page.content["plain"] = text.strip()
def replace_slug_references(
- text: str, regex: re.Pattern, merged_data: Dict[str, Dict[str, Any]]
+ text: str, regex: re.Pattern, merged_data: Dict[str, DocumentMetadata]
) -> str:
for match in regex.finditer(text):
ref_type, ref_short_id = match.groups()
full_match = match.group(0)
ref_id = next((k for k in merged_data if k.startswith(ref_short_id)), None)
if ref_id:
- replacement = f"/{merged_data[ref_id]['slug']}"
+ try:
+ replacement = f"/{merged_data[ref_id].slug}"
+ except AttributeError:
+ replacement = f"/{merged_data[ref_id].slug}"
text = text.replace(full_match, replacement)
return text
def replace_title_references(
- text: str, regex: re.Pattern, merged_data: Dict[str, Dict[str, Any]]
+ text: str, regex: re.Pattern, merged_data: Dict[str, DocumentMetadata]
) -> str:
for match in regex.finditer(text):
opening, ref_type, ref_short_id, comment, closing = match.groups()
full_match = match.group(0)
ref_id = next((k for k in merged_data if k.startswith(ref_short_id)), None)
if ref_id:
- replacement = merged_data[ref_id]["title"]
+ replacement = merged_data[ref_id].title
text = text.replace(full_match, replacement)
return text
def replace_cite_references(
- text: str, regex: re.Pattern, merged_data: Dict[str, Dict[str, Any]]
+ text: str, regex: re.Pattern, merged_data: Dict[str, DocumentMetadata]
) -> str:
for match in regex.finditer(text):
opening, ref_type, ref_short_id, comment, closing = match.groups()
full_match = match.group(0)
ref_id = next((k for k in merged_data if k.startswith(ref_short_id)), None)
if ref_id:
- replacement = f"[{merged_data[ref_id]["attribution"]["djot"]}] (/{merged_data[ref_id]["slug"]})"
+ replacement = f"[{merged_data[ref_id].attribution["djot"]}] (/{merged_data[ref_id].slug})"
text = text.replace(full_match, replacement)
return text
@@ -689,29 +762,32 @@ def replace_cite_references(
def replace_import_references(
text: str,
regex: re.Pattern,
- merged_data: Dict[str, Dict[str, Any]],
+ merged_data: Dict[str, DocumentMetadata],
key: str,
- page: Dict,
+ page: DocumentMetadata,
) -> str:
for match in regex.finditer(text):
opening, ref_type, ref_short_id, comment, closing = match.groups()
full_match = match.group(0)
ref_id = next((k for k in merged_data if k.startswith(ref_short_id)), None)
if ref_id:
- ref_text = merged_data[ref_id]["content"]["plain"]
+ ref_text = merged_data[ref_id].content["plain"]
if ref_type == "import::":
replacement = ref_text
elif ref_type == "aside::":
- ref_title = merged_data[ref_id]["title"]
- ref_slug = merged_data[ref_id]["slug"]
- ref_location = merged_data[ref_id].get("location", "")
- location_string = (
- " ⚕ "
- + ref_location.get("city")
- + ", "
- + ref_location.get("country")
- or ""
- )
+ ref_title = merged_data[ref_id].title
+ ref_slug = merged_data[ref_id].slug
+ ref_location = merged_data[ref_id].location
+ if ref_location:
+ location_string = (
+ " ⚕ "
+ + ref_location.get("city")
+ + ", "
+ + ref_location.get("country")
+ or ""
+ )
+ else:
+ location_string = ""
replacement = (
f'{{.aside}}\n{':'*78}\n'
f'{ref_text}\\\n'
@@ -722,18 +798,22 @@ def replace_import_references(
)
else:
raise ValueError(f"Unrecognised reference type: {ref_type}")
- if not page.get("status", "") == "draft":
- merged_data[ref_id]["backlinks"].add(key)
+ if not page.status == "draft":
+ merged_data[ref_id].links["backlinks"].add(key)
text = text.replace(full_match, replacement)
return text
def process_reference_links(
- text: str, regex: re.Pattern, merged_data: Dict[str, Dict[str, Any]], key: str
+ text: str, regex: re.Pattern, merged_data: Dict[str, DocumentMetadata], key: str
) -> str:
for ref_text_match, _, ref_type, ref_short_id in regex.findall(text):
match = f"[{ref_text_match}]({ref_type}{ref_short_id})"
- ref_id = next((k for k in merged_data if k.startswith(ref_short_id)), None)
+ ref_id = next(
+ (k for k in merged_data.keys() if k.startswith(ref_short_id)), None
+ )
+ if ref_id is None:
+ print(f"No match found for {ref_short_id}")
if not ref_id:
raise ValueError(
@@ -746,16 +826,16 @@ def process_reference_links(
)
ref_text = get_reference_text(ref_text_match, merged_data[ref_id])
- ref_slug = f"/{merged_data[ref_id]['slug']}"
+ ref_slug = f"/{merged_data[ref_id].slug}"
if ref_type == "link::":
try:
# Double quotes within a page title are escaped so that they don't break the HTML 'title' element
- ref_title = f"{merged_data[ref_id]['title']} | {merged_data[ref_id]['created'].strftime('%B %Y')}".replace(
+ ref_title = f"{merged_data[ref_id].title} | {merged_data[ref_id].created.strftime('%B %Y')}".replace(
'"', '\\"'
)
except KeyError:
- ref_title = merged_data[ref_id]["title"].replace('"', '\\"')
+ ref_title = merged_data[ref_id].title.replace('"', '\\"')
replacement = f'[{ref_text}]({ref_slug}){{title="{ref_title}"}}'
elif ref_type == "img::":
replacement = f"[{ref_text}]({ref_slug})"
@@ -778,18 +858,18 @@ def process_reference_links(
return text
-def get_reference_text(ref_text_match: str, ref_data: Dict) -> str:
+def get_reference_text(ref_text_match: str, ref_data) -> str:
if ref_text_match.startswith("::") or ref_text_match == "":
- return ref_data.get("title")
+ return ref_data.title
return ref_text_match
-def create_quote_replacement(ref_data: Dict, ref_slug: str) -> str:
- ref_src = ref_data["attribution"]["djot"]
+def create_quote_replacement(ref_data: DocumentMetadata, ref_slug: str) -> str:
+ ref_src = ref_data.attribution["djot"]
try:
- ref_text = ref_data["source"]["text"].replace("\n\n", "\n> \n> ").strip()
+ ref_text = ref_data.source["text"].replace("\n\n", "\n> \n> ").strip()
except:
- print(f"Error creating quote replacement: {ref_data["uid"]}")
+ print(f"Error creating quote replacement: {ref_data.uid}")
import sys
sys.exit()
@@ -808,10 +888,10 @@ Your browser does not support the video tag.
def generate_html(documents):
logger.info("Generating HTML")
for key, page in documents.items():
- if page.get("content", {}).get("plain"):
- page["content"]["html"] = run_jotdown(page["content"]["plain"])
- if page.get("source", {}).get("text"):
- page["source"]["html"] = run_jotdown(page["source"]["text"])
+ if page.content.get("plain"):
+ page.content["html"] = run_jotdown(page.content["plain"])
+ if page.source.get("text"):
+ page.source["html"] = run_jotdown(page.source["text"])
class LedgerLexer(RegexLexer):
@@ -841,7 +921,7 @@ class LedgerLexer(RegexLexer):
}
-def highlight_code(code: str, language: str = None) -> str:
+def highlight_code(code: str, language: str) -> str:
"""
Highlight code using Pygments with specified or guessed language.
"""
@@ -921,20 +1001,17 @@ def build_backlinks(documents, site):
FOOTNOTE_LINK_URL_RE = re.compile(r"\[.+?\]:\s\/(.*)", re.DOTALL)
interlink_count = 0
for key, page in documents.items():
- if (
- "nobacklinks" in page.get("options", "")
- or page.get("status", "") == "draft"
- ):
+ if "nobacklinks" in page.options or page.status == "draft":
continue
- logger.debug(page["filename"])
+ logger.debug(page.filepath)
- text = page.get("content", {}).get("plain")
+ text = page.content.get("plain")
# Skip if no main content
if not text:
continue
- interlinks = set(documents[key]["interlinks"])
+ interlinks = set(documents[key].links["internal"])
combined_refs = INLINE_LINK_RE.findall(text) + FOOTNOTE_LINK_URL_RE.findall(
text
@@ -950,11 +1027,28 @@ def build_backlinks(documents, site):
continue
logger.warning(f"\nKeyError in {page['title']} ({key}): {slug}")
- documents[key]["interlinks"] = list(interlinks)
+ documents[key].links["internal"] = interlinks
for interlink_key in interlinks:
- documents[interlink_key]["backlinks"].add(key)
+ documents[interlink_key].links["backlinks"].add(key)
- return interlink_count
+ for key, page in documents.items():
+ # Sort interlinks based on published dates
+ documents[key].links["internal"] = sorted(
+ documents[key].links["internal"],
+ key=lambda x: documents[x].available,
+ reverse=True, # Most recent first
+ )
+ # Sort backlinks based on published dates
+ documents[key].links["backlinks"] = sorted(
+ documents[key].links["backlinks"],
+ key=lambda x: documents[x].available,
+ reverse=True, # Most recent first
+ )
+
+ """
+ TODO: REMOVE SITE.BACKLINKS in favour a 'stats' or 'count' (templates will need updating
+ """
+ site.backlinks += interlink_count
def should_ignore_slug(slug):
@@ -966,7 +1060,7 @@ def should_ignore_slug(slug):
def build_collections(
- documents: Dict[str, Dict[str, Any]], site: SiteMetadata
+ documents: Dict[str, DocumentMetadata], site: SiteMetadata
) -> Tuple[Dict[str, List[Dict[str, Any]]], List[Dict[str, Any]]]:
collections = {
primary: []
@@ -978,24 +1072,24 @@ def build_collections(
sitemap = []
for key, page in sorted(
- documents.items(), key=lambda k_v: k_v[1]["available"], reverse=True
+ documents.items(), key=lambda k_v: k_v[1].available, reverse=True
):
- if page.get("status", "") == "draft":
+ if page.status == "draft":
collections["cd68b918-ac5f-4d6c-abb5-a55a0318846b"].append(page)
continue
- elif "nofeed" in page.get("options", []):
+ elif "nofeed" in page.options:
sitemap.append(page)
continue
else:
sitemap.append(page)
collections["everything"].append(page)
- collections[page["primary"]].append(page)
- collections[page["secondary"]].append(page)
+ collections[page.primary].append(page)
+ collections[page.secondary].append(page)
- for tag in page.get("tags", []):
+ for tag in page.tags:
collections[tag].append(page)
- if page["secondary"] in [
+ if page.secondary in [
"essays",
"wandering",
"rambling",
@@ -1008,8 +1102,8 @@ def build_collections(
def output_html(
- assets: Dict[str, Dict[str, Any]],
- documents: Dict[str, Dict[str, Any]],
+ assets: Dict[str, DocumentMetadata],
+ documents: Dict[str, DocumentMetadata],
collections: Dict[str, List[Dict[str, Any]]],
site: SiteMetadata,
env: Environment,
@@ -1018,7 +1112,7 @@ def output_html(
logger.info("Generating Hypertext")
for key, page in documents.items():
- template_file = page.get("layout", TEMPLATE_DEFAULT)
+ template_file = page.layout
template = env.get_template(template_file)
collection = build_page_collection(page, collections)
@@ -1028,28 +1122,29 @@ def output_html(
assets=assets,
collections=collections,
collection=collection,
- page=page,
+ page=asdict(page),
site=site,
)
- output_path = output_dir / page["slug"] / "index.html"
+ output_path = output_dir / page.slug / "index.html"
output_path.parent.mkdir(parents=True, exist_ok=True)
with open(output_path, "w") as f:
f.write(output)
- logger.debug(f" {page['filename']} >> {output_path}")
+ logger.debug(f" {page.filepath} >> {output_path}")
def build_page_collection(page, collections):
try:
collection = [
item
- for include in page["collection"]["include"]
+ for include in page.collection["include"]
for item in collections[include]
]
- return sorted(collection, key=lambda x: x["available"], reverse=True)
+ return sorted(collection, key=lambda x: x.available, reverse=True)
except KeyError:
+ print(f"Failed collection for {page.filepath}")
return []
@@ -1126,8 +1221,7 @@ async def main():
generate_html(documents)
# Build backlinks and collections
- interlink_count = build_backlinks(documents, site)
- site.backlinks += interlink_count
+ build_backlinks(documents, site)
collections, sitemap = build_collections(documents, site)
# Output HTML, feeds, and sitemap
@@ -1142,7 +1236,8 @@ async def main():
logger.info("Build complete!")
logger.info(f"Pages: {site.pagecount}")
logger.info(f"Words: {site.words["total"]}")
- logger.info(f"Interlinks: {interlink_count}")
+ logger.info(f"Internal links: {site.backlinks}")
+ logger.info(f"External links: {len(site.links["external"])}")
if __name__ == "__main__":